Peter Grafe
Meridian MMM Skills in Claude: The BlueAlpha Marketing Plugin
Ten MMM skills for Claude that turn your Meridian model into weekly decisions — health checks, budget sims, saturation maps, test roadmaps, and more.

TL;DR — The BlueAlpha MMM skills put a team of senior measurement analysts inside Claude. Ten skills connect directly to your Meridian marketing mix model and handle the jobs that turn a model into decisions — health-checking the model itself, reading weekly performance, mapping channel saturation, projecting launch timing, simulating budget shifts, comparing scenarios, routing channels into "act / test / fix" buckets, building quarterly test roadmaps, reconciling MMM with platform ROAS, and going deep on any single channel. Each skill follows the same loop: Analyze → Decide → Act. Under the hood, this is what BlueAlpha calls the Decision Engine — the system that turns every signal from your MMM into a real decision. This page is the index. Pick the skill that matches your job-to-be-done and jump to the prompt that runs it.
If you've spent six figures on a marketing mix model, you've felt the gap. You have a beautiful posterior. You have channel ROIs with credible intervals. You have a model your data science team is proud of. And every Monday morning, the planner asks: "so what do I actually do this week?" — and the model goes silent. Because a model is not a decision.
The BlueAlpha MMM skills close that gap. Each one is an agent that turns one slice of the model into a real call: trust the channel or test it, scale it or cut it, launch it now or wait, ship the bold plan or the defensive one. The skills don't replace your data scientist — they extend the model's reach so the entire growth team can act on it without re-asking the data scientist every time.
This isn't a new MMM. It's the missing layer between the MMM you already have and the spend decisions you make every week. That layer is what BlueAlpha calls the Decision Engine — and the MMM skills are how it lands.
All ten MMM skills in the BlueAlpha Marketing Plugin
Here's every MMM skill in the plugin with a one-liner. Each one is an agent that owns a specific decision surface — grouped below by the kind of question it answers.
Read what's happening — the foundational analysis layer:
mmm-health-check— Trust-grades the model itself across convergence, prior dominance, decomposition coherence, recency, and fit. Lead any conversation with the grade; never act on a model nobody has audited.mmm-performance-digest— The Monday-morning MMM read. Scoreboard, period-over-period change, per-channel ROI table, three-paragraph narrative. The recurring artifact your leadership actually reads.mmm-channel-deep-dive— Single-channel report card. Average ROI, marginal ROI, saturation position, adstock decay, trust diagnostics, and a clear cut / hold / scale / test verdict for one channel at a time.
Decide where the money goes — the planning layer:
mmm-saturation-report— Maps where every channel sits on its response curve. Surfaces the headroom triplet (where the next dollar earns the most) and the pruning triplet (where the current dollars are wasted).mmm-launch-timing— "If I launch this on Monday, when do I see the impact?" Combines adstock half-life with saturation curves to project a week-by-week impact ramp, time-to-50%, time-to-80%, and steady-state per channel.mmm-budget-reallocator— Simulates a proposed budget shift against the model's posterior and projects revenue lift with credible intervals. The closed-loop "should I actually move this money?" workflow.mmm-scenario-planner— Runs 3–5 candidate budget plans side-by-side with comparison-matrix output. The quarterly planning artifact you bring to the leadership review.
Decide what to trust — the confidence and testing layer:
mmm-trust-router— Per-channel classifier: Trust MMM (act directly), Validate first (test before acting), or Model insufficient (fix before deciding). Tells you which channels' reads are decision-grade and which need an incrementality test.mmm-test-roadmap— Turns the trust-router output into a sequenced quarterly testing calendar — which tests run in which weeks, packed by priority and budget, with pre-staged expected lifts as test priors.mmm-attribution-reconciler— Cross-references MMM channel ROI against platform-reported ROAS (Google Ads, Meta, etc.). Tags each channel as Agree, Platform overclaims, or Platform underclaims — and routes disagreements straight into the test roadmap.
Analyze → Decide → Act
Every MMM skill follows the same loop, the same one the Google Ads skills and TikTok skills follow:
Analyze — The agent pulls from your live Meridian posterior: ROI, marginal ROI, saturation curves, adstock parameters, prior-posterior comparisons, reconciled performance tables. You don't go digging through the model; the agent brings the relevant slice to you.
Decide — The agent produces a recommendation with the signal that backs it. Every recommendation includes the credible interval, the trust caveat, and the rationale. You see the data, the logic, and the confidence level before you act.
Act — The agent produces a deployment-ready output: a reallocation table you can hand to the activation layer, a test card you can hand to the incrementality runner, a one-page channel verdict you can hand to the channel owner. Not a slide in a deck; a spec you can ship the same day.
A single Head of Growth with the BlueAlpha MMM skills connected manages what used to require a measurement team plus a dedicated planner plus the eternal back-and-forth with the data scientist who actually understands the model.
Who the MMM skills are for
The plugin was built for people who work with MMMs, not for the people who build them. If any of the following sound like your week, this is built for you:
You're a Head of Growth and you have an MMM your data team is proud of, but every planning conversation still starts with "let me get the latest export from Maria."
You're a CMO and you need to defend the marketing budget to a CFO who keeps asking "are you sure?" — and you want causal evidence underneath every answer, not a screenshot from Meta Ads Manager.
You're an MMM analyst tired of rebuilding the same reallocation memo every quarter, with the same caveats hand-written every time.
You're a measurement scientist who built the model and want the rest of the org to be able to use it without you in the room.
Every skill is designed around the same principle: the human stays in the loop, Claude does the heavy lifting. The skills surface trust grades, present scorecards, build calendars, and prepare specs for your review.
BlueAlpha delivers the plugin in two modes. Self-Drive means your team uses the agents directly inside Claude — you own the decisions, BlueAlpha onboards, models, and stays close. Co-Pilot means a senior BlueAlpha growth partner runs the loop for you, reading what the agents surface and telling you exactly what to do. Same Decision Engine either way. The choice is who's in the seat — your team or ours.
How to pick the right skill
If you need to… | Run this skill |
|---|---|
Decide whether to trust the MMM at all this quarter |
|
Write the Monday-morning MMM update |
|
Go deep on one channel for a quarterly review |
|
Find which channels are saturated and which have headroom |
|
Answer "when will the new channel start showing up?" |
|
Move $50K from Meta to YouTube and see what happens |
|
Compare three budget options and pick one |
|
Sort channels into "act directly" vs "needs a test first" |
|
Build the quarterly incrementality testing calendar |
|
Reconcile what Google Ads is claiming vs what the MMM says |
|
How does the BlueAlpha plugin connect to your Meridian MMM?
Every MMM skill in the BlueAlpha Marketing Plugin is backed by an MCP connector that gives Claude direct, permissioned access to your Meridian model artifacts. MCP-native means the whole system lives inside Claude, Codex, or any AI workspace your team already uses — no separate dashboard to check, no model export to email around.
The BlueAlpha MMM connector gives Claude the ability to:
List every Meridian model registered in your workspace (production models plus sandbox).
Pull model summaries — channels, training time range, MCMC config, convergence diagnostics.
Read average ROI, marginal ROI, saturation curves, adstock parameters, and prior-posterior comparisons for any channel.
Compute reconciled performance tables matching what's in your BlueAlpha dashboard.
Run budget reallocation simulations against the posterior and return projected revenue lifts with 90% credible intervals.
Generate response curves at any operating point, with KPI-to-revenue conversion via the registered RPK schema.
Surface weekly channel contribution histories across the training window for trend and decomposition analysis.
The connector handles authentication, model loading, posterior caching, and reconciliation against your registered actuals. One sign-in, no model pickles to share, no config files. The model your data team trained becomes the model your planning team can talk to.
Getting connected
There are two pieces to install: the BlueAlpha MCP connector (so Claude can read your Meridian model and your Google Ads data) and the BlueAlpha Marketing Plugin itself (the skills that put that data to work). Total setup time is about a minute. Steps 1 and 3 are the same regardless of which Claude product you use; Step 2 has two paths depending on whether you're in Cowork or Claude Code.
Step 1 — Install the BlueAlpha MCP connector
Open Settings in the Claude desktop app
Go to Connectors → Add custom connector
Name it:
BlueAlpha MCPURL:
https://mcp.bluealpha.ai/mcpClick Connect and sign in with your BlueAlpha account
That single sign-in wires Claude up to your Meridian models (and your Google Ads accounts, if you have them). No keys, no IDs, no config files.
Step 2 — Install the plugin
Pick the path that matches the Claude product you're using.
Option A — Cowork (drag-and-drop)
Click Releases on the right rail and open the latest release (currently v0.4.0)
Expand Assets and click
bluealpha-marketing-plugin.pluginto downloadDrag the downloaded file into an open Cowork session and click Install when prompted
That's it. No CLI, no settings menu — one drag.
Option B — Claude Code (slash commands)
Inside Claude Code, run these two commands:
/plugin marketplace add <https://github.com/bluealpha-labs/bluealpha-plugins.git> /plugin install bluealpha-marketing-plugin
/plugin marketplace add <https://github.com/bluealpha-labs/bluealpha-plugins.git> /plugin install bluealpha-marketing-plugin
The first registers the GitHub repo as a marketplace; the second installs the plugin from it. The same plugin contains both the Google Ads skills and the MMM skills — you install once, the right skill triggers based on what you ask.
Step 3 — Try a skill
Invoking a skill is as simple as typing something like:
"Run a health check on my net_sales MMM and tell me if I can trust it for this quarter's planning."
Claude will route that to the right skill, load the workflow, and walk you through the Analyze → Decide → Act loop.
Skill reference — example prompts
Every skill is invoked with a sentence. Below is a copy-paste prompt for each one, plus a screenshot from a real run on a production MMM model (net_sales, 10 channels, 104 weeks of training data) so you know what output to expect.
mmm-health-check — should I trust this model at all?
Trust-grade my
net_salesMMM. Tell me whether the model is decision-grade, what's prior-dominated, and what the data scientist needs to fix before this quarter's planning.
The skill produces an overall A/B/C/F grade plus a subgrade breakdown across seven dimensions: convergence, recency, holdout validation, prior independence, decomposition coherence, reconciliation gap, and channel-level plausibility. Lead every other MMM conversation with this grade.

Real example from our dry-run on net_sales: the model landed at B — Convergence and Holdout flagged "Cannot verify" because sample_stats and holdout strategy weren't persisted in the trace; Prior Independence failed because 10 of 10 channels were prior-dominated on the adstock parameter; Reconciliation Gap passed cleanly. Result: usable model, but every downstream recommendation needs the prior-dominance caveat attached.
mmm-performance-digest — the Monday-morning MMM read
Generate the monthly performance digest for
net_sales. Trailing 4 weeks vs prior 4 weeks. Format: exec scoreboard, per-channel ROI table, three-paragraph narrative.
The skill produces a scoreboard with revenue, spend, and ROI period-over-period, a per-channel scoreboard sorted by spend share, and a three-paragraph narrative — what happened, channel detail, what to watch.
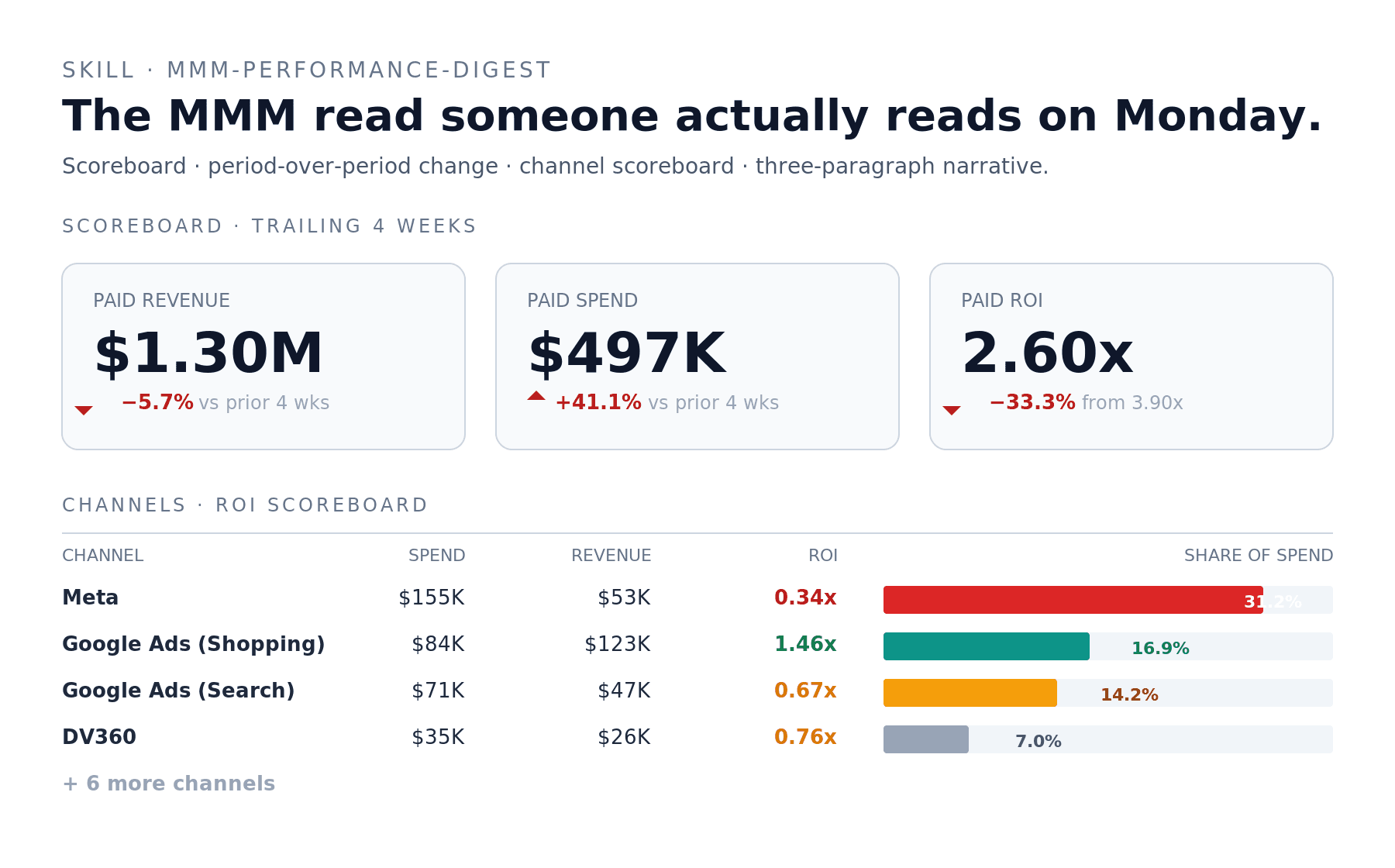
Real example: trailing 4 weeks of net_sales showed paid spend up 41% while paid revenue declined 5.7%, reconciled ROI compressing from 3.9x to 2.6x. The narrative paragraph the skill produced led with that story (not buried in a per-channel table) and named Meta — 31% of paid spend, 0.34x ROI in the window — as the primary contributor.
mmm-channel-deep-dive — the single-channel report card
Give me the full read on Meta in
net_sales— ROI, marginal ROI, saturation position, adstock decay, trust diagnostics, and a clear verdict.
The skill produces a one-page report card with the channel's current state, ROI table, saturation gauge, adstock summary, trust diagnostics per parameter, and a one-paragraph verdict landing on cut / hold / scale / test.
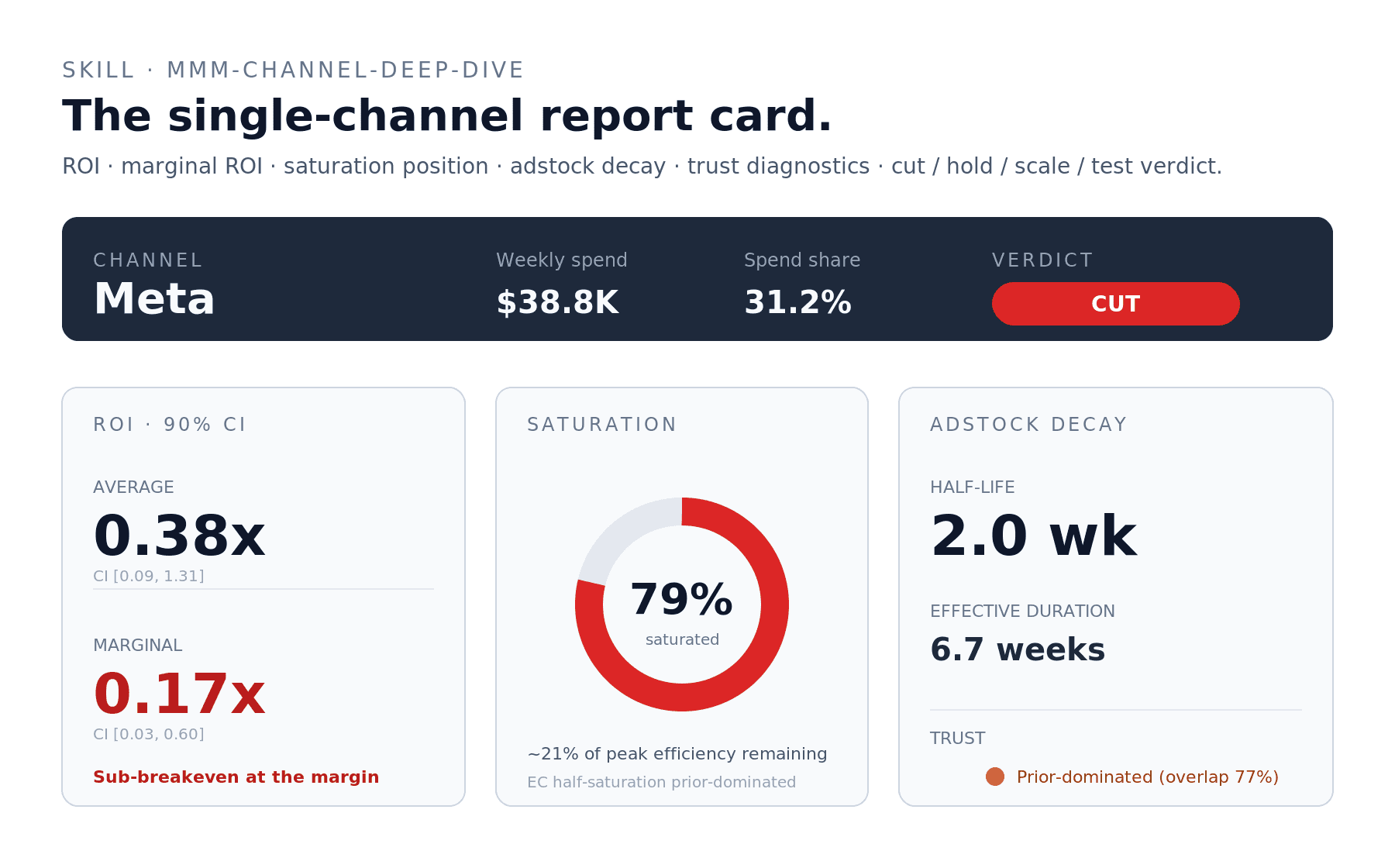
Real example: Meta in net_sales ran an average ROI of 0.38x with marginal ROI at 0.17x — sub-breakeven at the margin. 78.8% saturated. Adstock half-life 2.0 weeks, but the adstock parameter is prior-dominated so the timing read carries a caveat. Verdict: Cut, by 30–40% as a first move, with reallocation to Google Ads (Shopping). Run an incrementality test on the cut to confirm Meta isn't picking up halo effects the MMM is missing.
mmm-saturation-report — where each channel sits on its curve
Show me where every channel in
net_salessits on its response curve. Surface the headroom triplet (scale candidates) and the pruning triplet (cut candidates).
The skill returns an overlaid Hill saturation chart with operating-point markers per channel, plus a verdict sidebar grouping channels into Scale / Cut / Verify-first.
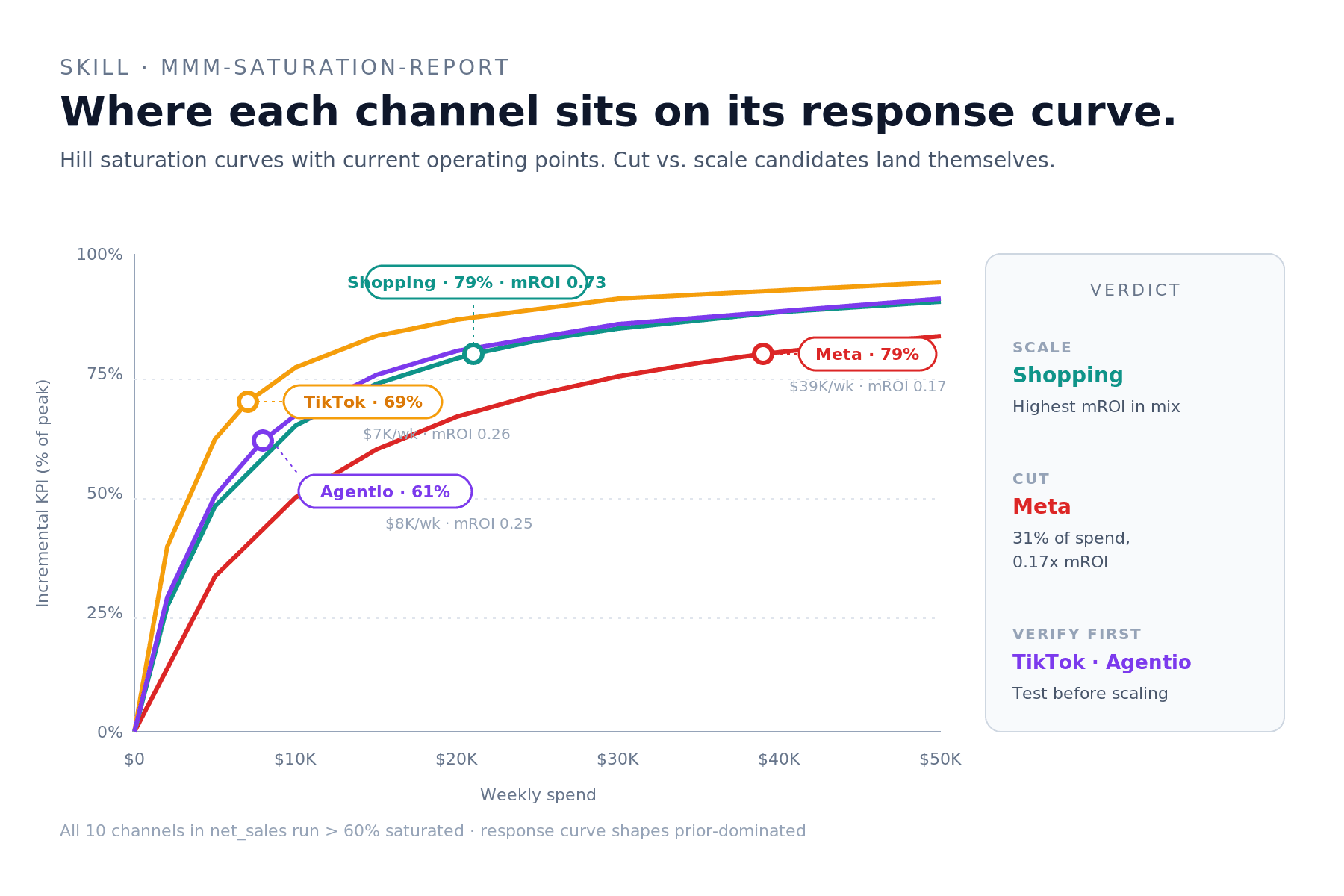
Real example: in net_sales, every channel ran above 60% saturation — so there is no "headroom" in the strict sense. The best scale candidate was Google Ads (Shopping) at 79% saturation but 0.73 mROI (the highest in the mix); the strongest cut candidate was Meta at 79% saturation and 0.17 mROI (the lowest). The verify-first list flagged TikTok and Agentio — small bases with wide credible intervals on their saturation curves; scaling them without a test would be model extrapolation.
mmm-launch-timing — when will I see the impact?
If I ramp TikTok from $7.6K/week to $12K/week starting Monday in the
net_salesmodel, when will I see the impact? Give me a week-by-week ramp.
The skill produces a week-by-week impact projection combining the channel's adstock half-life with its saturation curve position, plus the time-to-50%, time-to-80%, and steady-state markers.
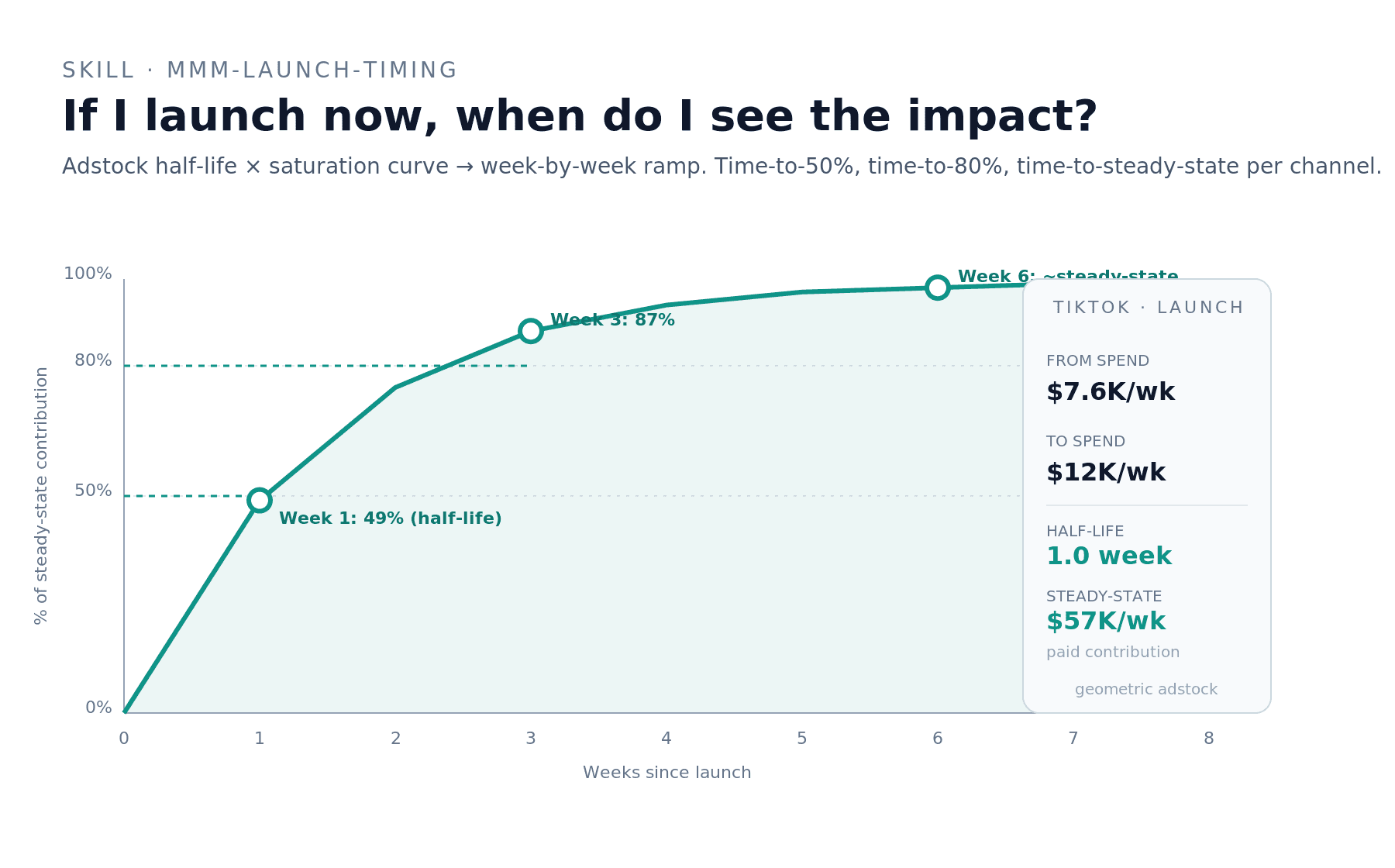
Real example: TikTok's adstock half-life of 1.0 week means 50% of steady-state lift in week 1, 87% by week 3, and full ~98% steady-state by week 6. Steady-state projected weekly contribution at $12K spend: ~$57K (vs. ~$38K today). Caveat: TikTok's adstock parameter is prior-dominated, so the model is reporting the prior median (0.5) rather than learning carry-over from the data; the timing read is directional, the magnitude is uncertain.
mmm-budget-reallocator — simulate the shift before you make it
Run a defensive reallocation in
net_sales: cut Meta by 36%, cut TikTok by 21%, redirect to Google Ads (Shopping). Same total spend ±5%. Project revenue impact with credible intervals.
The skill takes a proposed budget dict, runs it through Meridian's posterior, and returns a before/after table with projected revenue lift and a 90% credible interval. It also runs sensitivity checks at half and double the proposed magnitude.
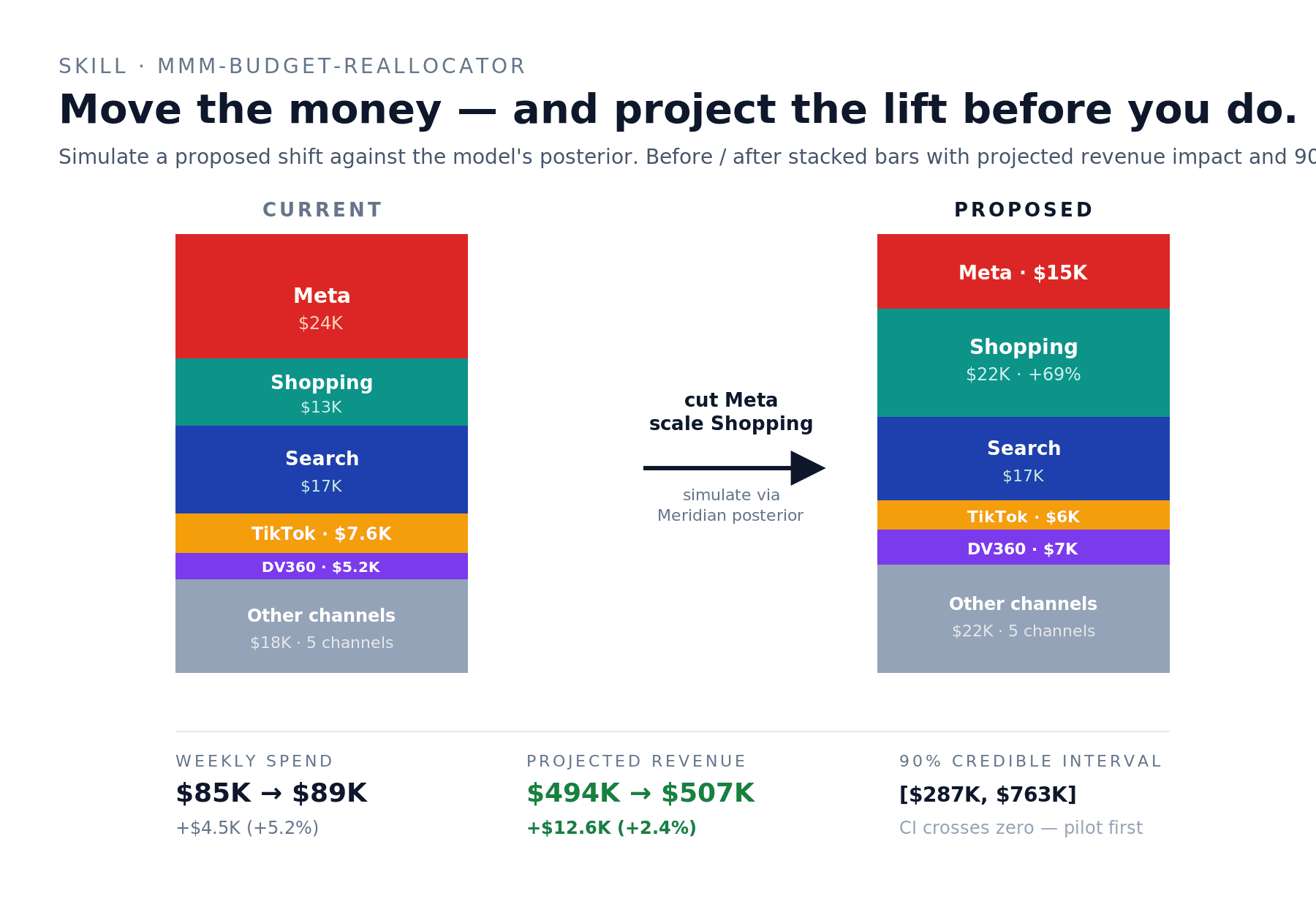
Real example: the defensive reallocation above (Meta $24K → $15K, Shopping $13K → $22K, plus minor shifts) projected +$12.6K/week revenue (+2.4%) at virtually flat total spend ($85K → $89K). The 90% credible interval — $287K to $763K — crossed zero on the low side, meaning directionally favorable but not bet-the-farm confident. Skill recommendation: run smaller pilot version first before committing the full shift.
mmm-scenario-planner — compare alternatives side-by-side
Compare three scenarios in
net_sales: status quo, defensive reallocation (cut Meta+TikTok, scale Shopping), and bold expansion (+43% spend across the board). Side-by-side matrix with credible intervals.
The skill runs each scenario through the posterior, produces a comparison matrix with median projection and 90% CI per scenario, layers in a trust caveat per scenario based on which channels are involved, and lands on a clear recommendation.
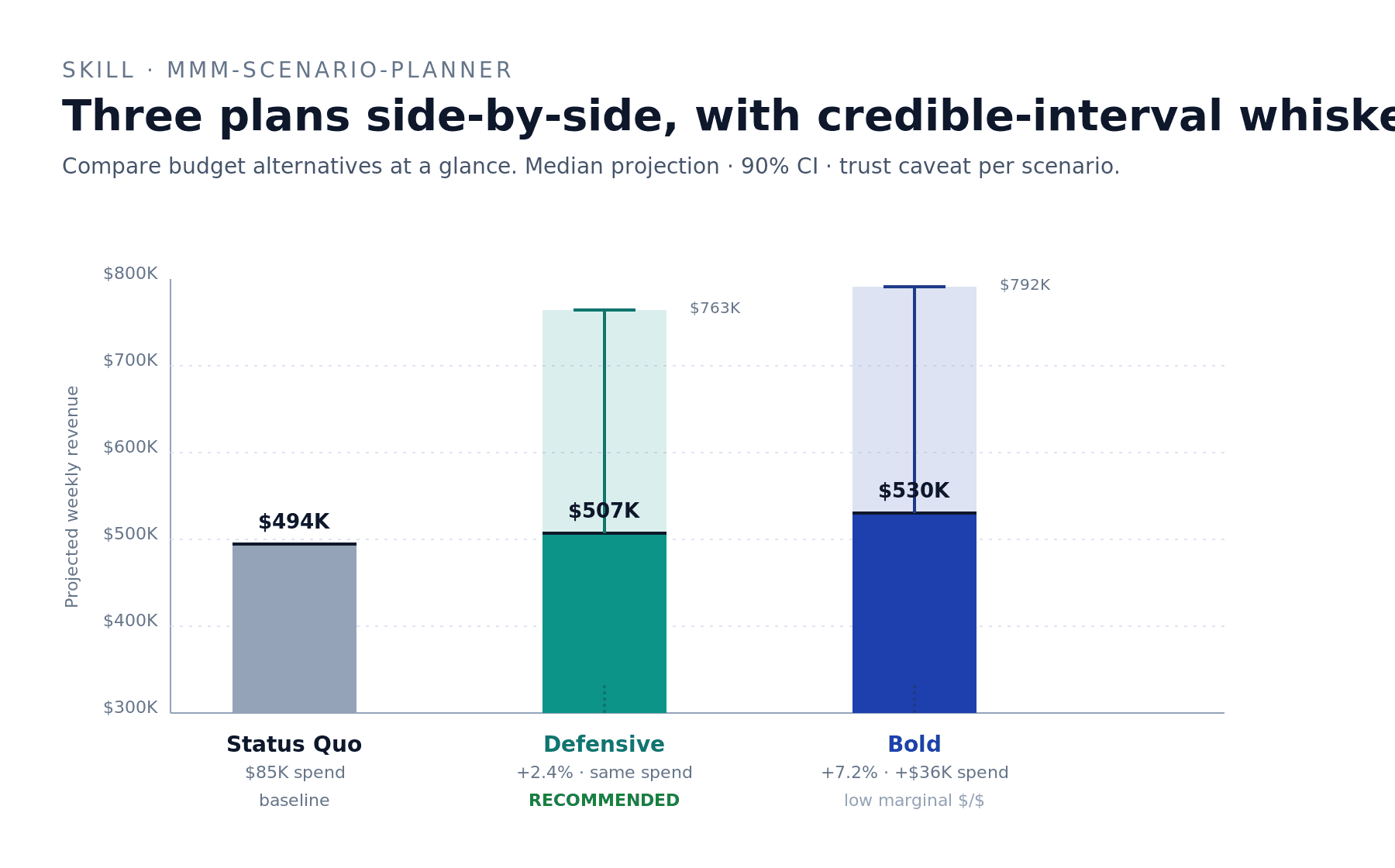
Real example: Status Quo $494K/week. Defensive $507K (+2.4% at flat spend). Bold $530K (+7.2% but at +$36K spend — incremental dollars buying revenue at roughly breakeven). On net_sales's wide credible intervals, neither scenario's CI excluded zero. The skill's recommendation: Defensive. Better cost-adjusted bet, no exposure to additional spend on prior-dominated channels, headline projection $13K/week revenue lift for nearly flat spend.
mmm-trust-router — which channels can I act on?
Route every channel in
net_salesinto Trust MMM / Validate first / Model insufficient based on per-channel confidence. For the Validate-first channels, pre-stage the test priors.
The skill computes six per-channel inputs — credible interval width, prior-posterior overlap, training-period spend variation, channel correlation with confounds, operating point relative to training range, adstock parameter convergence — and routes each channel into one of three buckets.
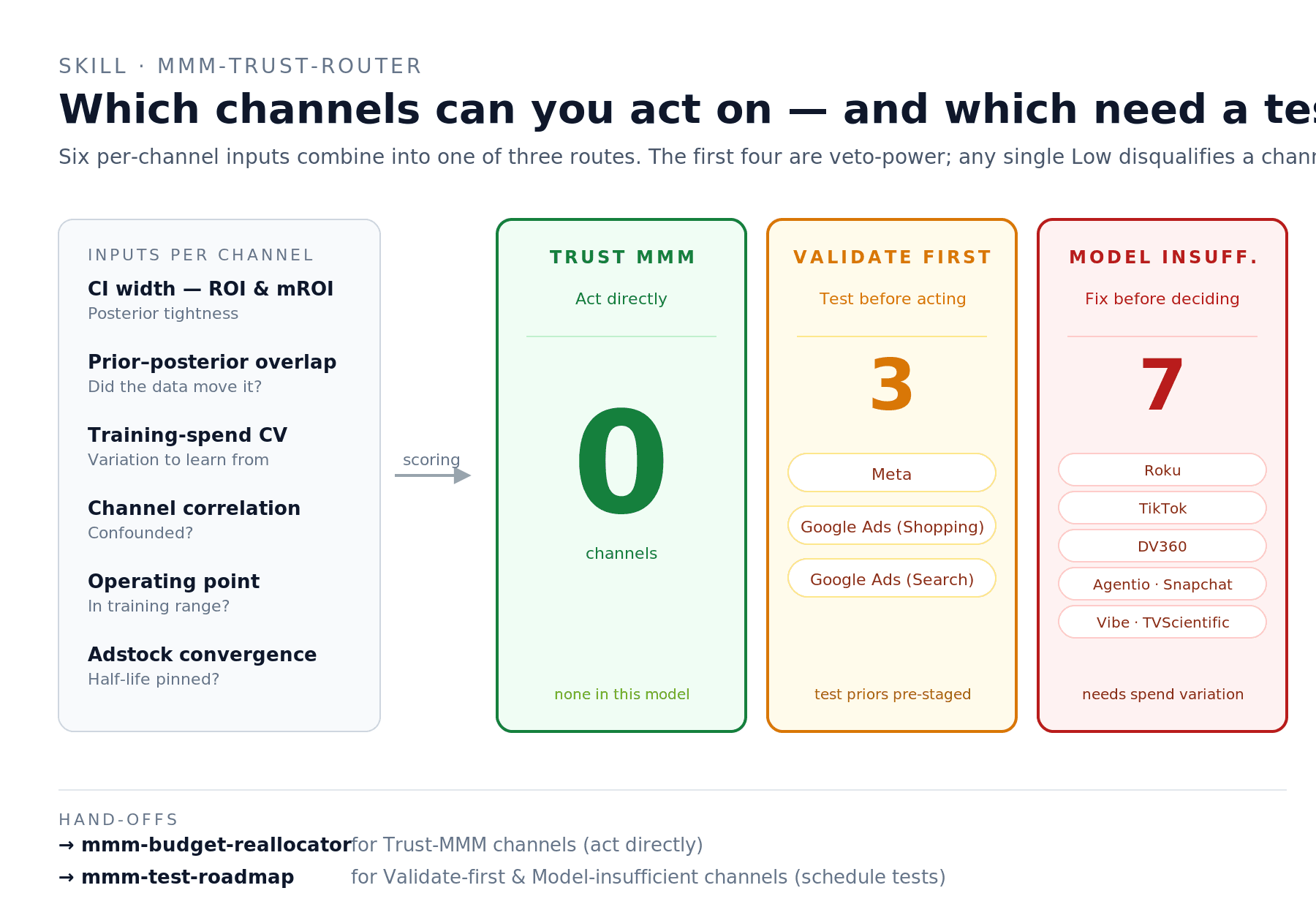
Real example: on net_sales, the routing came out 0 Trust MMM / 3 Validate first / 7 Model insufficient. Validate-first: Meta, Google Ads (Shopping), Google Ads (Search) — wide CIs but clearest spend variation and minimal confounds, moderate confidence on direction. Model insufficient: the other seven — wide ROI CIs combined with prior-dominated response curves and moderate-to-high channel correlations (the test-channel cluster of Agentio / Snapchat / Vibe / TVScientific co-moves at r = 0.50–0.67). This routing is consistent with the B health-check grade — a B-grade model should produce mostly Validate-first or worse.
mmm-test-roadmap — the quarterly testing calendar
Build me a Q1 test roadmap for
net_sales. Test budget $200K, concurrency cap 2. Pull trust-router output and pack the highest-priority tests into the calendar.
The skill scores every candidate test on information value (CI width × distance from prior × channel size) and business value (decision blocked, recurring spend exposure, leadership scrutiny), then packs the highest-priority tests into a 13-week calendar subject to budget and concurrency constraints.

Real example: Q1 roadmap for net_sales slotted three tests — Meta cut validation (weeks 1–6, $35K), Google Ads (Shopping) scale validation (weeks 3–12, $42K), TikTok structured spend ramp (weeks 9–13, $30K). Google Ads (Search) hold validation got queued to Q2 because concurrency cap was the binding constraint. Total Q1 spend $107K of $200K; $93K reserved as buffer for surprise tests.
mmm-attribution-reconciler — MMM vs platform ROAS
Reconcile what Google Ads is saying about ROAS vs what the MMM says for every channel in
net_sales. Surface disagreements and route any test-worthy gaps to the roadmap.
The skill pulls platform ROAS from the connected Google Ads account (and accepts pasted Meta / TikTok / etc. numbers for the rest), pairs them with MMM channel ROI, tags each channel as Agree / Platform-overclaims / Platform-underclaims, and routes disagreements through the trust router.
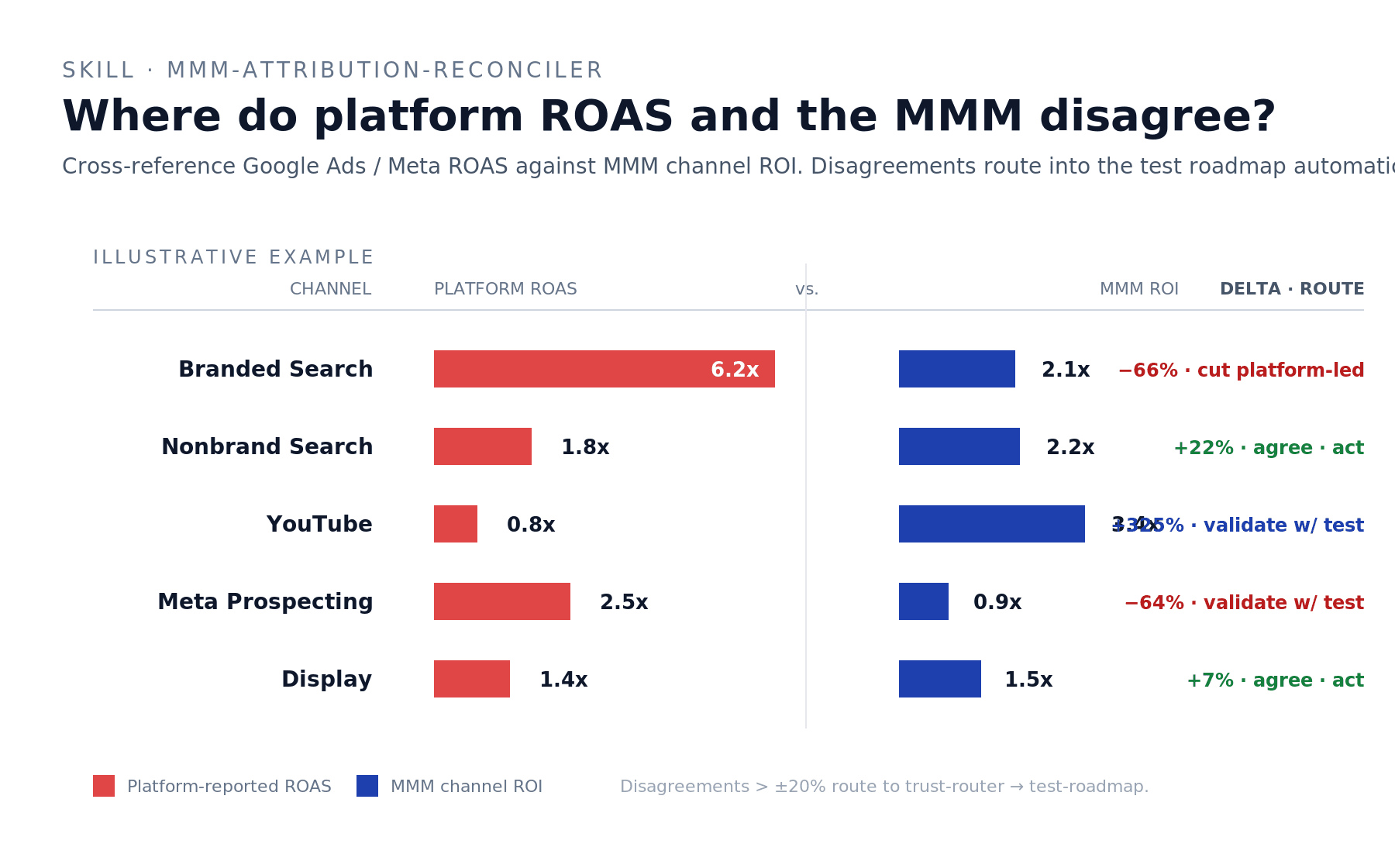
Illustrative example (the dry-run on net_sales didn't have Google Ads connected behind the MCP — when this skill runs on a fully connected stack, it produces a divergence chart per channel): Branded Search where Google says 6.2x ROAS but MMM says 2.1x — Platform overclaims by 66%, trust MMM, cut the platform-led budget recommendation. YouTube where Google says 0.8x but MMM says 3.4x — Platform underclaims by 325%, validate with a test before scaling. Display where both sources land near 1.5x — Agree, ship the decision either way.
Why aren't the BlueAlpha MMM skills just another marketing mix model?
There are two kinds of products in marketing measurement, and BlueAlpha is neither.
The first is rigorous but passive — the bespoke MMM consultancy that produces a beautiful posterior, hands you a slide deck, and disappears for the quarter. The math is right; nothing happens with it. The model sits in a pickle file or a hand-built dashboard, getting more wrong every week as the market moves.
The second is actionable but shallow — the platform attribution stack that produces fast recommendations from last-touch math that doesn't survive iOS privacy or a skeptical CFO. The recommendations are real-time and confidently wrong.
BlueAlpha is the third option: causal measurement underneath, real agents producing deployment-ready specs, MCP-native. Not a measurement vendor. Not a model in a slide deck. The decision layer underneath the model.
The difference shows up in results. When BlueAlpha ran incrementality tests for Cann, AppLovin's platform-reported ROAS was 4.77x, but the actual incremental lift was zero — saving Cann $480K per year in misallocated spend. For Klover, BlueAlpha's measurement cut Meta iOS spend by 50% with zero lost conversions, freeing budget to scale Apple Search Ads by 10x. For beehiiv, causal measurement caught a channel overreporting performance by 345%. For Pettable, nine months of causal measurement reduced blended CAC by 14%, unlocking $2.12M in annualized savings.
These aren't post-hoc readouts. They're decisions the Decision Engine makes — grounded in the incrementality the MMM measures, deployed via the skills the marketing team uses.
This is what we call Agentic-Led Growth — the GTM motion that follows Sales-Led and Product-Led Growth. The agents do the analytical work. The human makes the call. The engine delivers.
FAQ
Do I need to bring my own MMM?
If you have an MMM already, the BlueAlpha MMM skills work against it via the Meridian standard. If you don't, BlueAlpha can build one for you — the Decision Engine's full value shows up when the measurement and the activation layers are operated as a single system.
What if my MMM isn't built in Meridian?
The current connector reads Meridian model artifacts. If you're running a different framework (Robyn, internal Stan, vendor model), reach out — we've ported other formats and the skill layer is model-agnostic.
Will the skills change my MMM?
No. The skills are read-only against the model itself. They read the posterior, compute derived metrics, run simulations against the posterior, and produce recommendations. They do not retrain, modify, or write back to the model. The data science team retains full control of the model artifact.
Will the skills make changes to my Google Ads or other ad accounts automatically?
Not currently. The MMM skills produce reallocation recommendations, scenario comparisons, test cards, and channel verdicts. You execute the spend changes through your activation layer — whether that's the BlueAlpha Google Ads skills, an in-house team, or your agency. On-platform execution is on the roadmap.
How often should I run each skill?
mmm-health-check and mmm-performance-digest are weekly or monthly. mmm-saturation-report and mmm-trust-router are monthly or quarterly. mmm-test-roadmap is quarterly. mmm-channel-deep-dive, mmm-launch-timing, mmm-budget-reallocator, and mmm-scenario-planner are event-triggered — when a planning conversation, a launch, or a leadership ask demands them. mmm-attribution-reconciler is quarterly, or any time the platform attribution stack changes.
My MMM has wide credible intervals. Can the skills still produce a decision?
Yes — and the skills surface the uncertainty rather than hiding it. The trust router will route uncertain channels into Validate-first, the budget reallocator and scenario planner attach the 90% CI to every projection, and the health-check skill will tell you which subgrades are failing. You'll get a recommendation paired with the right level of confidence — and a path to tighten it (usually an incrementality test).
Can I use the skills with multiple MMMs?
Yes. The plugin supports any number of registered Meridian models. You specify the model name in your prompt — "...for the net_sales model" or "...for net_new_customers" — and the skill routes against that posterior.
Which Claude product do I run it in?
The plugin works inside Cowork mode in the Claude desktop app and in Claude Code. Both support plugin installation from marketplaces. MCP-native means the Decision Engine goes wherever Claude goes.
Do the MMM skills work with the Google Ads skills in the same plugin?
Yes — they ship in the same plugin (bluealpha-marketing-plugin), and they're designed to compose. The natural planning loop is: mmm-health-check → mmm-trust-router → mmm-attribution-reconciler → mmm-test-roadmap → mmm-scenario-planner → mmm-budget-reallocator → mmm-launch-timing → hand off to incrementality-test-runner (Google Ads skill) for any test scheduled in the roadmap.
What's Agentic-Led Growth?
Agentic-Led Growth (ALG) is a go-to-market motion in which specialized AI agents handle the analytical and executional work that previously required large teams. It follows Sales-Led Growth and Product-Led Growth as the next evolution of how companies scale. Instead of adding headcount or building self-serve funnels, ALG deploys agents that turn every signal in the marketing stack — including the MMM — into real decisions and deliver deployment-ready specs. BlueAlpha is the Decision Engine that powers it.
Your next step
Pick the skill that matches the question you're trying to answer today, copy the prompt above, and run it in Claude. If you're new to the MMM skills, start with mmm-health-check — it's the right first move on any model you haven't audited, and it produces the trust grade that every downstream skill's caveats hang on.
If your model is fresh from a B-grade or better, mmm-trust-router is the second prompt to run. It tells you which channels you can act on directly and which need an incrementality test before you bet meaningful budget on them. From there, the planning loop runs itself.
If you haven't installed the plugin yet, setup takes about a minute.
If you'd rather see the skills run on your model before installing, book a walkthrough.
TL;DR — The BlueAlpha MMM skills put a team of senior measurement analysts inside Claude. Ten skills connect directly to your Meridian marketing mix model and handle the jobs that turn a model into decisions — health-checking the model itself, reading weekly performance, mapping channel saturation, projecting launch timing, simulating budget shifts, comparing scenarios, routing channels into "act / test / fix" buckets, building quarterly test roadmaps, reconciling MMM with platform ROAS, and going deep on any single channel. Each skill follows the same loop: Analyze → Decide → Act. Under the hood, this is what BlueAlpha calls the Decision Engine — the system that turns every signal from your MMM into a real decision. This page is the index. Pick the skill that matches your job-to-be-done and jump to the prompt that runs it.
If you've spent six figures on a marketing mix model, you've felt the gap. You have a beautiful posterior. You have channel ROIs with credible intervals. You have a model your data science team is proud of. And every Monday morning, the planner asks: "so what do I actually do this week?" — and the model goes silent. Because a model is not a decision.
The BlueAlpha MMM skills close that gap. Each one is an agent that turns one slice of the model into a real call: trust the channel or test it, scale it or cut it, launch it now or wait, ship the bold plan or the defensive one. The skills don't replace your data scientist — they extend the model's reach so the entire growth team can act on it without re-asking the data scientist every time.
This isn't a new MMM. It's the missing layer between the MMM you already have and the spend decisions you make every week. That layer is what BlueAlpha calls the Decision Engine — and the MMM skills are how it lands.
All ten MMM skills in the BlueAlpha Marketing Plugin
Here's every MMM skill in the plugin with a one-liner. Each one is an agent that owns a specific decision surface — grouped below by the kind of question it answers.
Read what's happening — the foundational analysis layer:
mmm-health-check— Trust-grades the model itself across convergence, prior dominance, decomposition coherence, recency, and fit. Lead any conversation with the grade; never act on a model nobody has audited.mmm-performance-digest— The Monday-morning MMM read. Scoreboard, period-over-period change, per-channel ROI table, three-paragraph narrative. The recurring artifact your leadership actually reads.mmm-channel-deep-dive— Single-channel report card. Average ROI, marginal ROI, saturation position, adstock decay, trust diagnostics, and a clear cut / hold / scale / test verdict for one channel at a time.
Decide where the money goes — the planning layer:
mmm-saturation-report— Maps where every channel sits on its response curve. Surfaces the headroom triplet (where the next dollar earns the most) and the pruning triplet (where the current dollars are wasted).mmm-launch-timing— "If I launch this on Monday, when do I see the impact?" Combines adstock half-life with saturation curves to project a week-by-week impact ramp, time-to-50%, time-to-80%, and steady-state per channel.mmm-budget-reallocator— Simulates a proposed budget shift against the model's posterior and projects revenue lift with credible intervals. The closed-loop "should I actually move this money?" workflow.mmm-scenario-planner— Runs 3–5 candidate budget plans side-by-side with comparison-matrix output. The quarterly planning artifact you bring to the leadership review.
Decide what to trust — the confidence and testing layer:
mmm-trust-router— Per-channel classifier: Trust MMM (act directly), Validate first (test before acting), or Model insufficient (fix before deciding). Tells you which channels' reads are decision-grade and which need an incrementality test.mmm-test-roadmap— Turns the trust-router output into a sequenced quarterly testing calendar — which tests run in which weeks, packed by priority and budget, with pre-staged expected lifts as test priors.mmm-attribution-reconciler— Cross-references MMM channel ROI against platform-reported ROAS (Google Ads, Meta, etc.). Tags each channel as Agree, Platform overclaims, or Platform underclaims — and routes disagreements straight into the test roadmap.
Analyze → Decide → Act
Every MMM skill follows the same loop, the same one the Google Ads skills and TikTok skills follow:
Analyze — The agent pulls from your live Meridian posterior: ROI, marginal ROI, saturation curves, adstock parameters, prior-posterior comparisons, reconciled performance tables. You don't go digging through the model; the agent brings the relevant slice to you.
Decide — The agent produces a recommendation with the signal that backs it. Every recommendation includes the credible interval, the trust caveat, and the rationale. You see the data, the logic, and the confidence level before you act.
Act — The agent produces a deployment-ready output: a reallocation table you can hand to the activation layer, a test card you can hand to the incrementality runner, a one-page channel verdict you can hand to the channel owner. Not a slide in a deck; a spec you can ship the same day.
A single Head of Growth with the BlueAlpha MMM skills connected manages what used to require a measurement team plus a dedicated planner plus the eternal back-and-forth with the data scientist who actually understands the model.
Who the MMM skills are for
The plugin was built for people who work with MMMs, not for the people who build them. If any of the following sound like your week, this is built for you:
You're a Head of Growth and you have an MMM your data team is proud of, but every planning conversation still starts with "let me get the latest export from Maria."
You're a CMO and you need to defend the marketing budget to a CFO who keeps asking "are you sure?" — and you want causal evidence underneath every answer, not a screenshot from Meta Ads Manager.
You're an MMM analyst tired of rebuilding the same reallocation memo every quarter, with the same caveats hand-written every time.
You're a measurement scientist who built the model and want the rest of the org to be able to use it without you in the room.
Every skill is designed around the same principle: the human stays in the loop, Claude does the heavy lifting. The skills surface trust grades, present scorecards, build calendars, and prepare specs for your review.
BlueAlpha delivers the plugin in two modes. Self-Drive means your team uses the agents directly inside Claude — you own the decisions, BlueAlpha onboards, models, and stays close. Co-Pilot means a senior BlueAlpha growth partner runs the loop for you, reading what the agents surface and telling you exactly what to do. Same Decision Engine either way. The choice is who's in the seat — your team or ours.
How to pick the right skill
If you need to… | Run this skill |
|---|---|
Decide whether to trust the MMM at all this quarter |
|
Write the Monday-morning MMM update |
|
Go deep on one channel for a quarterly review |
|
Find which channels are saturated and which have headroom |
|
Answer "when will the new channel start showing up?" |
|
Move $50K from Meta to YouTube and see what happens |
|
Compare three budget options and pick one |
|
Sort channels into "act directly" vs "needs a test first" |
|
Build the quarterly incrementality testing calendar |
|
Reconcile what Google Ads is claiming vs what the MMM says |
|
How does the BlueAlpha plugin connect to your Meridian MMM?
Every MMM skill in the BlueAlpha Marketing Plugin is backed by an MCP connector that gives Claude direct, permissioned access to your Meridian model artifacts. MCP-native means the whole system lives inside Claude, Codex, or any AI workspace your team already uses — no separate dashboard to check, no model export to email around.
The BlueAlpha MMM connector gives Claude the ability to:
List every Meridian model registered in your workspace (production models plus sandbox).
Pull model summaries — channels, training time range, MCMC config, convergence diagnostics.
Read average ROI, marginal ROI, saturation curves, adstock parameters, and prior-posterior comparisons for any channel.
Compute reconciled performance tables matching what's in your BlueAlpha dashboard.
Run budget reallocation simulations against the posterior and return projected revenue lifts with 90% credible intervals.
Generate response curves at any operating point, with KPI-to-revenue conversion via the registered RPK schema.
Surface weekly channel contribution histories across the training window for trend and decomposition analysis.
The connector handles authentication, model loading, posterior caching, and reconciliation against your registered actuals. One sign-in, no model pickles to share, no config files. The model your data team trained becomes the model your planning team can talk to.
Getting connected
There are two pieces to install: the BlueAlpha MCP connector (so Claude can read your Meridian model and your Google Ads data) and the BlueAlpha Marketing Plugin itself (the skills that put that data to work). Total setup time is about a minute. Steps 1 and 3 are the same regardless of which Claude product you use; Step 2 has two paths depending on whether you're in Cowork or Claude Code.
Step 1 — Install the BlueAlpha MCP connector
Open Settings in the Claude desktop app
Go to Connectors → Add custom connector
Name it:
BlueAlpha MCPURL:
https://mcp.bluealpha.ai/mcpClick Connect and sign in with your BlueAlpha account
That single sign-in wires Claude up to your Meridian models (and your Google Ads accounts, if you have them). No keys, no IDs, no config files.
Step 2 — Install the plugin
Pick the path that matches the Claude product you're using.
Option A — Cowork (drag-and-drop)
Click Releases on the right rail and open the latest release (currently v0.4.0)
Expand Assets and click
bluealpha-marketing-plugin.pluginto downloadDrag the downloaded file into an open Cowork session and click Install when prompted
That's it. No CLI, no settings menu — one drag.
Option B — Claude Code (slash commands)
Inside Claude Code, run these two commands:
/plugin marketplace add <https://github.com/bluealpha-labs/bluealpha-plugins.git> /plugin install bluealpha-marketing-plugin
The first registers the GitHub repo as a marketplace; the second installs the plugin from it. The same plugin contains both the Google Ads skills and the MMM skills — you install once, the right skill triggers based on what you ask.
Step 3 — Try a skill
Invoking a skill is as simple as typing something like:
"Run a health check on my net_sales MMM and tell me if I can trust it for this quarter's planning."
Claude will route that to the right skill, load the workflow, and walk you through the Analyze → Decide → Act loop.
Skill reference — example prompts
Every skill is invoked with a sentence. Below is a copy-paste prompt for each one, plus a screenshot from a real run on a production MMM model (net_sales, 10 channels, 104 weeks of training data) so you know what output to expect.
mmm-health-check — should I trust this model at all?
Trust-grade my
net_salesMMM. Tell me whether the model is decision-grade, what's prior-dominated, and what the data scientist needs to fix before this quarter's planning.
The skill produces an overall A/B/C/F grade plus a subgrade breakdown across seven dimensions: convergence, recency, holdout validation, prior independence, decomposition coherence, reconciliation gap, and channel-level plausibility. Lead every other MMM conversation with this grade.
Real example from our dry-run on net_sales: the model landed at B — Convergence and Holdout flagged "Cannot verify" because sample_stats and holdout strategy weren't persisted in the trace; Prior Independence failed because 10 of 10 channels were prior-dominated on the adstock parameter; Reconciliation Gap passed cleanly. Result: usable model, but every downstream recommendation needs the prior-dominance caveat attached.
mmm-performance-digest — the Monday-morning MMM read
Generate the monthly performance digest for
net_sales. Trailing 4 weeks vs prior 4 weeks. Format: exec scoreboard, per-channel ROI table, three-paragraph narrative.
The skill produces a scoreboard with revenue, spend, and ROI period-over-period, a per-channel scoreboard sorted by spend share, and a three-paragraph narrative — what happened, channel detail, what to watch.
Real example: trailing 4 weeks of net_sales showed paid spend up 41% while paid revenue declined 5.7%, reconciled ROI compressing from 3.9x to 2.6x. The narrative paragraph the skill produced led with that story (not buried in a per-channel table) and named Meta — 31% of paid spend, 0.34x ROI in the window — as the primary contributor.
mmm-channel-deep-dive — the single-channel report card
Give me the full read on Meta in
net_sales— ROI, marginal ROI, saturation position, adstock decay, trust diagnostics, and a clear verdict.
The skill produces a one-page report card with the channel's current state, ROI table, saturation gauge, adstock summary, trust diagnostics per parameter, and a one-paragraph verdict landing on cut / hold / scale / test.
Real example: Meta in net_sales ran an average ROI of 0.38x with marginal ROI at 0.17x — sub-breakeven at the margin. 78.8% saturated. Adstock half-life 2.0 weeks, but the adstock parameter is prior-dominated so the timing read carries a caveat. Verdict: Cut, by 30–40% as a first move, with reallocation to Google Ads (Shopping). Run an incrementality test on the cut to confirm Meta isn't picking up halo effects the MMM is missing.
mmm-saturation-report — where each channel sits on its curve
Show me where every channel in
net_salessits on its response curve. Surface the headroom triplet (scale candidates) and the pruning triplet (cut candidates).
The skill returns an overlaid Hill saturation chart with operating-point markers per channel, plus a verdict sidebar grouping channels into Scale / Cut / Verify-first.
Real example: in net_sales, every channel ran above 60% saturation — so there is no "headroom" in the strict sense. The best scale candidate was Google Ads (Shopping) at 79% saturation but 0.73 mROI (the highest in the mix); the strongest cut candidate was Meta at 79% saturation and 0.17 mROI (the lowest). The verify-first list flagged TikTok and Agentio — small bases with wide credible intervals on their saturation curves; scaling them without a test would be model extrapolation.
mmm-launch-timing — when will I see the impact?
If I ramp TikTok from $7.6K/week to $12K/week starting Monday in the
net_salesmodel, when will I see the impact? Give me a week-by-week ramp.
The skill produces a week-by-week impact projection combining the channel's adstock half-life with its saturation curve position, plus the time-to-50%, time-to-80%, and steady-state markers.
Real example: TikTok's adstock half-life of 1.0 week means 50% of steady-state lift in week 1, 87% by week 3, and full ~98% steady-state by week 6. Steady-state projected weekly contribution at $12K spend: ~$57K (vs. ~$38K today). Caveat: TikTok's adstock parameter is prior-dominated, so the model is reporting the prior median (0.5) rather than learning carry-over from the data; the timing read is directional, the magnitude is uncertain.
mmm-budget-reallocator — simulate the shift before you make it
Run a defensive reallocation in
net_sales: cut Meta by 36%, cut TikTok by 21%, redirect to Google Ads (Shopping). Same total spend ±5%. Project revenue impact with credible intervals.
The skill takes a proposed budget dict, runs it through Meridian's posterior, and returns a before/after table with projected revenue lift and a 90% credible interval. It also runs sensitivity checks at half and double the proposed magnitude.
Real example: the defensive reallocation above (Meta $24K → $15K, Shopping $13K → $22K, plus minor shifts) projected +$12.6K/week revenue (+2.4%) at virtually flat total spend ($85K → $89K). The 90% credible interval — $287K to $763K — crossed zero on the low side, meaning directionally favorable but not bet-the-farm confident. Skill recommendation: run smaller pilot version first before committing the full shift.
mmm-scenario-planner — compare alternatives side-by-side
Compare three scenarios in
net_sales: status quo, defensive reallocation (cut Meta+TikTok, scale Shopping), and bold expansion (+43% spend across the board). Side-by-side matrix with credible intervals.
The skill runs each scenario through the posterior, produces a comparison matrix with median projection and 90% CI per scenario, layers in a trust caveat per scenario based on which channels are involved, and lands on a clear recommendation.
Real example: Status Quo $494K/week. Defensive $507K (+2.4% at flat spend). Bold $530K (+7.2% but at +$36K spend — incremental dollars buying revenue at roughly breakeven). On net_sales's wide credible intervals, neither scenario's CI excluded zero. The skill's recommendation: Defensive. Better cost-adjusted bet, no exposure to additional spend on prior-dominated channels, headline projection $13K/week revenue lift for nearly flat spend.
mmm-trust-router — which channels can I act on?
Route every channel in
net_salesinto Trust MMM / Validate first / Model insufficient based on per-channel confidence. For the Validate-first channels, pre-stage the test priors.
The skill computes six per-channel inputs — credible interval width, prior-posterior overlap, training-period spend variation, channel correlation with confounds, operating point relative to training range, adstock parameter convergence — and routes each channel into one of three buckets.
Real example: on net_sales, the routing came out 0 Trust MMM / 3 Validate first / 7 Model insufficient. Validate-first: Meta, Google Ads (Shopping), Google Ads (Search) — wide CIs but clearest spend variation and minimal confounds, moderate confidence on direction. Model insufficient: the other seven — wide ROI CIs combined with prior-dominated response curves and moderate-to-high channel correlations (the test-channel cluster of Agentio / Snapchat / Vibe / TVScientific co-moves at r = 0.50–0.67). This routing is consistent with the B health-check grade — a B-grade model should produce mostly Validate-first or worse.
mmm-test-roadmap — the quarterly testing calendar
Build me a Q1 test roadmap for
net_sales. Test budget $200K, concurrency cap 2. Pull trust-router output and pack the highest-priority tests into the calendar.
The skill scores every candidate test on information value (CI width × distance from prior × channel size) and business value (decision blocked, recurring spend exposure, leadership scrutiny), then packs the highest-priority tests into a 13-week calendar subject to budget and concurrency constraints.
Real example: Q1 roadmap for net_sales slotted three tests — Meta cut validation (weeks 1–6, $35K), Google Ads (Shopping) scale validation (weeks 3–12, $42K), TikTok structured spend ramp (weeks 9–13, $30K). Google Ads (Search) hold validation got queued to Q2 because concurrency cap was the binding constraint. Total Q1 spend $107K of $200K; $93K reserved as buffer for surprise tests.
mmm-attribution-reconciler — MMM vs platform ROAS
Reconcile what Google Ads is saying about ROAS vs what the MMM says for every channel in
net_sales. Surface disagreements and route any test-worthy gaps to the roadmap.
The skill pulls platform ROAS from the connected Google Ads account (and accepts pasted Meta / TikTok / etc. numbers for the rest), pairs them with MMM channel ROI, tags each channel as Agree / Platform-overclaims / Platform-underclaims, and routes disagreements through the trust router.
Illustrative example (the dry-run on net_sales didn't have Google Ads connected behind the MCP — when this skill runs on a fully connected stack, it produces a divergence chart per channel): Branded Search where Google says 6.2x ROAS but MMM says 2.1x — Platform overclaims by 66%, trust MMM, cut the platform-led budget recommendation. YouTube where Google says 0.8x but MMM says 3.4x — Platform underclaims by 325%, validate with a test before scaling. Display where both sources land near 1.5x — Agree, ship the decision either way.
Why aren't the BlueAlpha MMM skills just another marketing mix model?
There are two kinds of products in marketing measurement, and BlueAlpha is neither.
The first is rigorous but passive — the bespoke MMM consultancy that produces a beautiful posterior, hands you a slide deck, and disappears for the quarter. The math is right; nothing happens with it. The model sits in a pickle file or a hand-built dashboard, getting more wrong every week as the market moves.
The second is actionable but shallow — the platform attribution stack that produces fast recommendations from last-touch math that doesn't survive iOS privacy or a skeptical CFO. The recommendations are real-time and confidently wrong.
BlueAlpha is the third option: causal measurement underneath, real agents producing deployment-ready specs, MCP-native. Not a measurement vendor. Not a model in a slide deck. The decision layer underneath the model.
The difference shows up in results. When BlueAlpha ran incrementality tests for Cann, AppLovin's platform-reported ROAS was 4.77x, but the actual incremental lift was zero — saving Cann $480K per year in misallocated spend. For Klover, BlueAlpha's measurement cut Meta iOS spend by 50% with zero lost conversions, freeing budget to scale Apple Search Ads by 10x. For beehiiv, causal measurement caught a channel overreporting performance by 345%. For Pettable, nine months of causal measurement reduced blended CAC by 14%, unlocking $2.12M in annualized savings.
These aren't post-hoc readouts. They're decisions the Decision Engine makes — grounded in the incrementality the MMM measures, deployed via the skills the marketing team uses.
This is what we call Agentic-Led Growth — the GTM motion that follows Sales-Led and Product-Led Growth. The agents do the analytical work. The human makes the call. The engine delivers.
FAQ
Do I need to bring my own MMM?
If you have an MMM already, the BlueAlpha MMM skills work against it via the Meridian standard. If you don't, BlueAlpha can build one for you — the Decision Engine's full value shows up when the measurement and the activation layers are operated as a single system.
What if my MMM isn't built in Meridian?
The current connector reads Meridian model artifacts. If you're running a different framework (Robyn, internal Stan, vendor model), reach out — we've ported other formats and the skill layer is model-agnostic.
Will the skills change my MMM?
No. The skills are read-only against the model itself. They read the posterior, compute derived metrics, run simulations against the posterior, and produce recommendations. They do not retrain, modify, or write back to the model. The data science team retains full control of the model artifact.
Will the skills make changes to my Google Ads or other ad accounts automatically?
Not currently. The MMM skills produce reallocation recommendations, scenario comparisons, test cards, and channel verdicts. You execute the spend changes through your activation layer — whether that's the BlueAlpha Google Ads skills, an in-house team, or your agency. On-platform execution is on the roadmap.
How often should I run each skill?
mmm-health-check and mmm-performance-digest are weekly or monthly. mmm-saturation-report and mmm-trust-router are monthly or quarterly. mmm-test-roadmap is quarterly. mmm-channel-deep-dive, mmm-launch-timing, mmm-budget-reallocator, and mmm-scenario-planner are event-triggered — when a planning conversation, a launch, or a leadership ask demands them. mmm-attribution-reconciler is quarterly, or any time the platform attribution stack changes.
My MMM has wide credible intervals. Can the skills still produce a decision?
Yes — and the skills surface the uncertainty rather than hiding it. The trust router will route uncertain channels into Validate-first, the budget reallocator and scenario planner attach the 90% CI to every projection, and the health-check skill will tell you which subgrades are failing. You'll get a recommendation paired with the right level of confidence — and a path to tighten it (usually an incrementality test).
Can I use the skills with multiple MMMs?
Yes. The plugin supports any number of registered Meridian models. You specify the model name in your prompt — "...for the net_sales model" or "...for net_new_customers" — and the skill routes against that posterior.
Which Claude product do I run it in?
The plugin works inside Cowork mode in the Claude desktop app and in Claude Code. Both support plugin installation from marketplaces. MCP-native means the Decision Engine goes wherever Claude goes.
Do the MMM skills work with the Google Ads skills in the same plugin?
Yes — they ship in the same plugin (bluealpha-marketing-plugin), and they're designed to compose. The natural planning loop is: mmm-health-check → mmm-trust-router → mmm-attribution-reconciler → mmm-test-roadmap → mmm-scenario-planner → mmm-budget-reallocator → mmm-launch-timing → hand off to incrementality-test-runner (Google Ads skill) for any test scheduled in the roadmap.
What's Agentic-Led Growth?
Agentic-Led Growth (ALG) is a go-to-market motion in which specialized AI agents handle the analytical and executional work that previously required large teams. It follows Sales-Led Growth and Product-Led Growth as the next evolution of how companies scale. Instead of adding headcount or building self-serve funnels, ALG deploys agents that turn every signal in the marketing stack — including the MMM — into real decisions and deliver deployment-ready specs. BlueAlpha is the Decision Engine that powers it.
Your next step
Pick the skill that matches the question you're trying to answer today, copy the prompt above, and run it in Claude. If you're new to the MMM skills, start with mmm-health-check — it's the right first move on any model you haven't audited, and it produces the trust grade that every downstream skill's caveats hang on.
If your model is fresh from a B-grade or better, mmm-trust-router is the second prompt to run. It tells you which channels you can act on directly and which need an incrementality test before you bet meaningful budget on them. From there, the planning loop runs itself.
If you haven't installed the plugin yet, setup takes about a minute.
If you'd rather see the skills run on your model before installing, book a walkthrough.
